
parallelly 1.26.0: Fast, Concurrent Setup of Parallel Workers (Finally)
parallelly 1.26.0 is on CRAN. It comes with one major improvement and one new function:
The setup of parallel workers is now much faster, which comes from using a concurrent, instead of sequential, setup strategy
The new
freePort()can be used to find a TCP port that is currently available
Faster setup of local, parallel workers
In R 4.0.0, which was released in May 2020, parallel::makeCluster(n) gained the power of setting up the n local cluster nodes all at the same time, which greatly reduces to total setup time. Previously, because it was setting up the workers one after the other, which involved a lot of waiting for each worker to get ready. You can read about the details in the Socket Connections Update blog post by Tomas Kalibera and Luke Tierney on 2020-03-17.
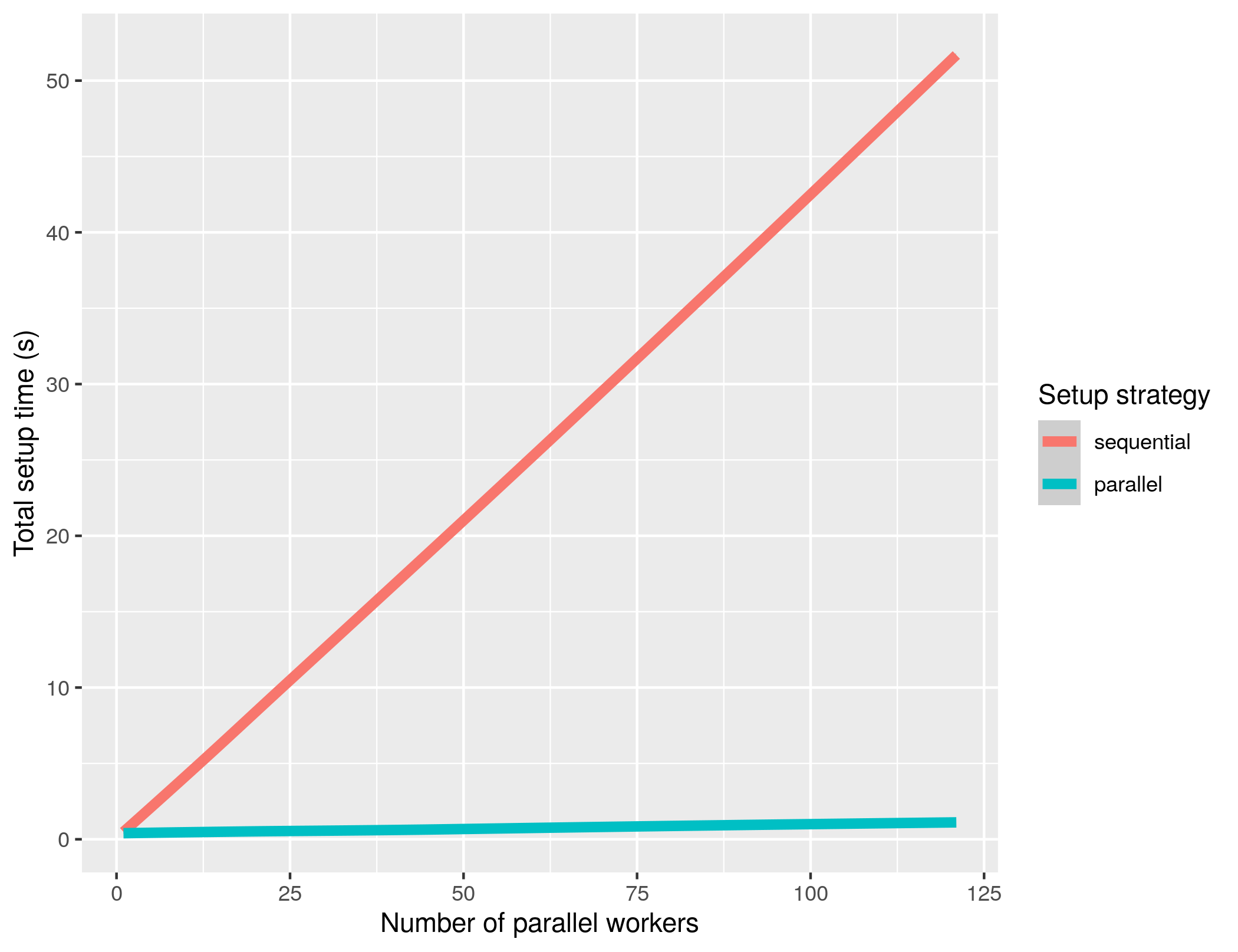
With this release of parallelly, parallelly::makeClusterPSOCK(n) gained the same skills. I benchmarked the new, default “parallel” setup strategy against the previous “sequential” strategy on a CentOS 7 Linux machine with 128 CPU cores and 512 GiB RAM while the machine was idle. I ran these benchmarks five times, which are summarized as smooth curves in the above figure. The variance between the replicate runs is tiny and the smooth curves appear almost linear. Assuming a linear relationship between setup time and number of cluster workers, a linear fit of gives a speedup of approximately 50 times on this machine. It took 52 seconds to set up 122 (sic!) workers when using the “sequential” approach, whereas it took only 1.1 seconds with the “parallel” approach. Not surprisingly, rerunning these benchmarks with parallel::makePSOCKcluster() instead gives nearly identical results.
Importantly, the “parallel” setup strategy, which is the new default, can only be used when setting up parallel workers running on the local machine. When setting up workers on external or remote machines, the “sequential” setup strategy will still be used.
If you’re using future and use
plan(multisession)
you’ll immediately benefit from this performance gain, because it relies on parallelly::makeClusterPSOCK() internally.
All credit for this improvement in parallelly and parallelly::makeClusterPSOCK() should go to Tomas Kalibera and Luke Tierney, who implemented support for this in R 4.0.0.
Edit 2021-06-11 and 2021-07-01: There’s a bug in R (>= 4.0.0 && <= 4.1.0) causing the new setup_strategy = "parallel" to fail in the RStudio Console on some systems. If you’re running RStudio Console and get “Error in makeClusterPSOCK(workers, …) : Cluster setup failed. 8 of 8 workers failed to connect.“, update to parallelly 1.26.1 released on 2021-06-30:
install.packages("parallelly")
which will work around this problem. Alternatively, you can manually set:
options(parallelly.makeNodePSOCK.setup_strategy = "sequential")
Comment: Note that I could only test with up to 122 parallel workers, and not 128, which is the number of CPU cores available on the test machine. The reason for this is that each worker consumes one R connection in the main R session, and R has a limit in the number of connection it can have open at any time. The typical R installation can only have 128 connections open, and three are always occupied by the standard input (stdin), the standard output (stdout), and the standard error (stderr). Thus, the absolute maximum number of workers I could use 125. However, because I used the progressr package to report on progress, and a few other things that consumed a few more connections, I could only test up to 122 workers. You can read more about this limit in ?parallelly::freeConnections, which also gives a reference for how to increase this limit by recompling R from source.
Find an available TCP port
I’ve also added freePort(), which will find a random port in [1024,65535] that is currently not occupied by another process on the machine. For example,
> freePort()
[1] 30386
> freePort()
[1] 37882
Using this function to pick a TCP port at random lowers the risk of trying to use a port already occupied as when using just sample(1024:65535, size=1).
Just like parallel::makePSOCKcluster(), parallelly::makeClusterPSOCK() still uses sample(11000:11999, size=1) to find a random port. I want freePort() to get some more mileage and CRAN validation before switching over, but the plan is to use freePort() by default in the next release of parallelly.
Over and out!
