
Package: matrixStats 0.13.1 - Methods that Apply to Rows and Columns of a Matrix (and Vectors)
A new release 0.13.1 of matrixStats is now on CRAN. The source code is available on GitHub.
What does it do?
The matrixStats package provides highly optimized functions for computing common summaries over rows and columns of matrices, e.g. rowQuantiles(). There are also functions that operate on vectors, e.g. logSumExp(). Their implementations strive to minimize both memory usage and processing time. They are often remarkably faster compared to good old apply() solutions. The calculations are mostly implemented in C, which allow us to optimize(*) beyond what is possible to do in plain R. The package installs out-of-the-box on all common operating systems, including Linux, OS X and Windows.
The following example computes the median of the columns in a 20-by-500 matrix
> library("matrixStats")
> X <- matrix(rnorm(20 * 500), nrow = 20, ncol = 500)
> stats <- microbenchmark::microbenchmark(colMedians = colMedians(X),
+ `apply+median` = apply(X, MARGIN = 2, FUN = median), unit = "ms")
> stats
Unit: milliseconds
expr min lq mean median uq max neval cld
colMedians 0.41 0.45 0.49 0.47 0.5 0.75 100 a
apply+median 21.50 22.77 25.59 23.86 26.2 107.12 100 b
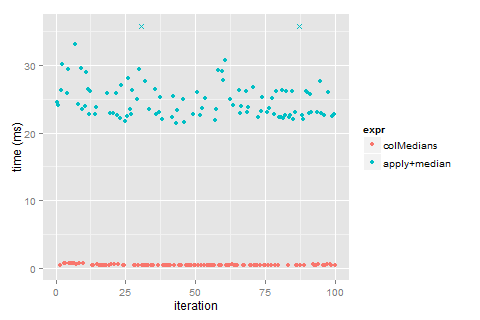
It shows that colMedians() is ~51 times faster than apply(..., MARGIN = 2, FUN = median) in this particular case. The relative gain varies with matrix shape, so you should benchmark with your configurations. You can also play around with the benchmark reports that are under development, e.g. html <- matrixStats:::benchmark("colRowMedians"); !html.
What is new?
With this release, all the functions run faster than ever before and at the same time use less memory than ever before, which in turn means that now even larger data matrices can be processed without having to upgrade the RAM. A few small bugs have also been fixed and some “missing” functions have been added to the R API. This update is part of a long-term tune-up that started back in June 2014. Most of the major groundwork has already been done, but there is still room for improvements. If you’re using matrixStats functions in your package already now, you should see some notable speedups for those function calls, especially compared to what was available back in June. For instance, rowMins() is now 5-20 times faster than functions such as base::pmin.int() whereas in the past they performed roughly the same.
I’ve also added a large number of new package tests; the R and C source code coverage has recently gone up from 59% to 96% (… and counting). Some of the bugs were discovered as part of this effort. Here a special thank should go out to Jim Hester for his great work on covr, which provides me with on-the-fly coverage reports via Coveralls. (You can run covr locally or via GitHub + Travis CI, which is very easy if you’re already up and running there. Try it!) I would also like to thank the R core team and the CRAN team for their continuous efforts on improving the package tests that we get via R CMD check but also via the CRAN farm (which occasionally catches code issues that I’m not always seeing on my end).
Footnote:
(*) One strategy for keeping the memory footprint at a minimum is to optimize the implementations for the integer and the numeric (double) data types separately. Because of this, a great number of data-type coercions are avoided, coercions that otherwise would consume precious memory due to temporarily allocated copies, but also precious processing time because the garbage collector later would have to spend time cleaning up the mess. The new weightedMean() function, which is many times faster than stats::weighted.mean(), is one of several cases where this strategy is particular helpful.
Links
- CRAN page: http://cran.r-project.org/package=matrixStats
- GitHub page: https://github.com/HenrikBengtsson/matrixStats
- Coveralls page: https://coveralls.io/r/HenrikBengtsson/matrixStats?branch=develop
- Bug reports: https://github.com/HenrikBengtsson/matrixStats/issues
- covr: https://github.com/jimhester/covr
